PS 자동화: 풀고 Push 하면 끝!(3)
알고리즘 학습 자동화의 Ollama 도입기
들어가며
기존 자동화 방식에서 문제 이름이 긴 경우, 패키지 이름 작성과 커밋 메세지 작성하는 데 소요되는 시간이 많다고 판단되어 이를 Ollma를 활용하여 더 편리하게 수정한 과정을 기록해보고자 한다.
기존의 방법과 한계
Leetcode의 1343. Number of Sub-arrays of Size K and Average Greater than or Equal to Threshold를 풀면서 문제 이름이 긴 경우, 코드 작성 전 후로 다른 소요시간이 많이 걸리는 것을 체감했다.
그간 작성해왔던 자동화 방식에서는 위의 경우, 다음과 같은 과정을 거치고 작업물을 push 해야한다.
- Leet_1343_Number of Sub-arrays of Size K and Average Greater than or Equal to Threshold 이름 복사
- 패키지 생성 후 Leet_1343Number of Sub-arrays of Size K and Average Greater than or Equal to Threshold 에 포함되어있는 띄어쓰기를 언더바() 혹은 - 로 직접 대체
- Solution 파일 작성
- git commit -m “feat: Leet_1343_Number of Sub-arrays of Size K and Average Greater than or Equal to Threshold” 커밋 메시지 작성
- push
단순하게 나는 13번의 띄어쓰기를 수기로 직접 언더바 처리하거나 띄어쓰기를 해야한다. 또한 커밋 메세지 또한 직접 작성해야하는데 이를 복사, 붙여넣기 하는 과정 또한 소요시간이 꽤 걸린다. 이를 도식화 하면 다음과 같다.
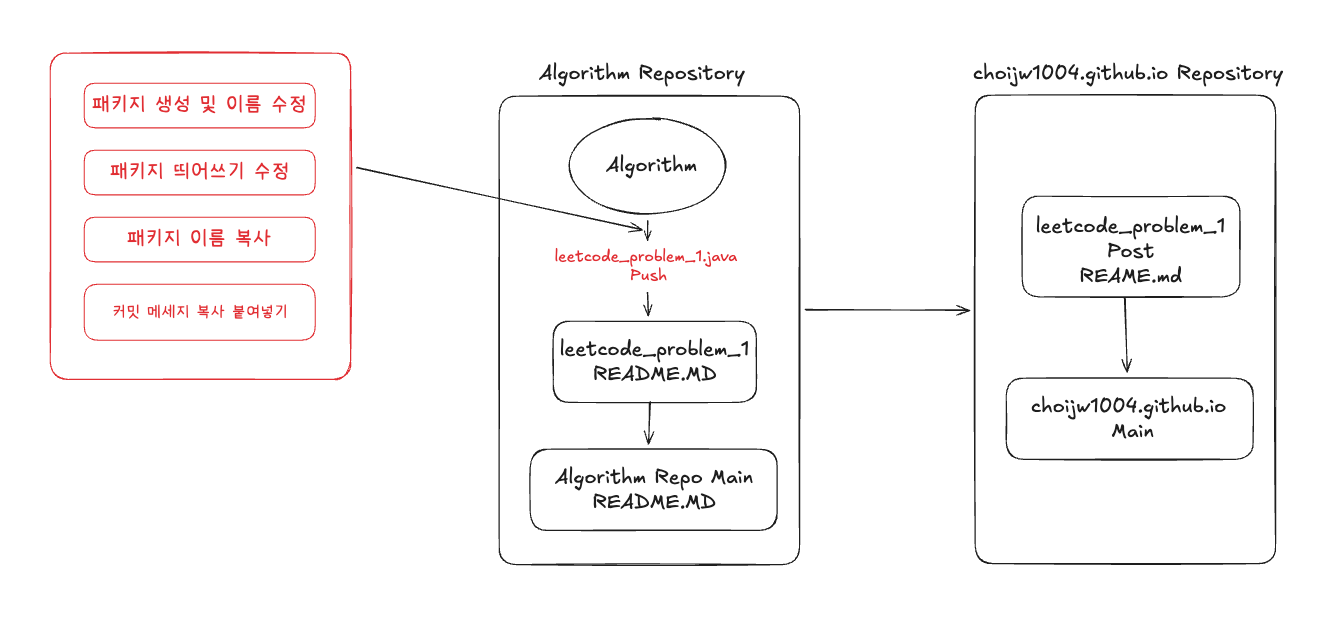
빨갛게 표시된 부분이 위에서 설명했던 일련의 과정이다.
PS를 위해 사용하고 있는 플랫폼은 백준, 리트코드, 프로그래머스이기도 하고 이를 전부 예외로 반영하고 스크립트를 수정하려면 까다롭다고 판단했고, 이러한 부분을 LLM을 활용하여 해결할 수 있다면 훨씬 더 효율적인 자동화가 이루어질 것이라고 생각했다.
LLM을 활용하여 git add. , git commit 만 작성하면 기존에 자동화 했던 부분(main readme 업데이트, github blog post 작성 및 push acitons)까지 자동화 하고 싶었다.
git hooks
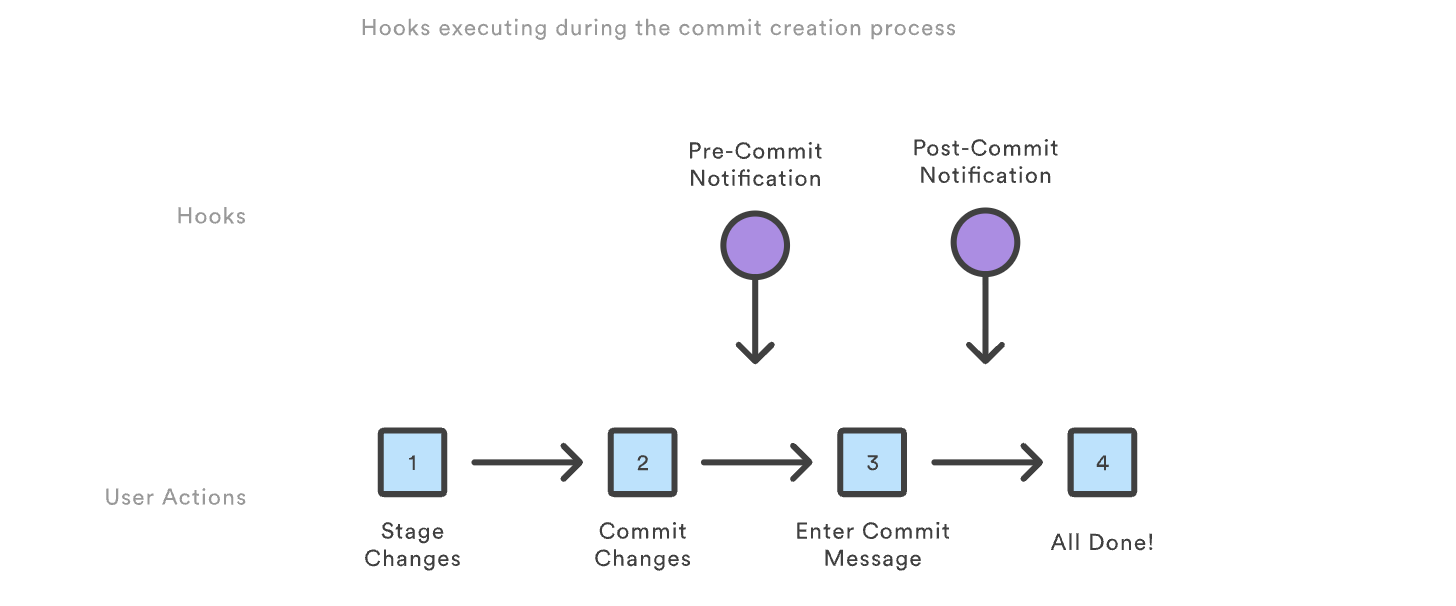
이를 위해 사용했던 개념은 git hooks 이다. git hooks git의 특정 이벤트(stage, commit, push)가 발생할 때 자동으로 실행되는 스크립트 이다.
실제로 깃 루트 디렉토리에 ./git/hooks에는 수정할 수 있는 샘플 파일을 확인할 수 있다. 
여기서 나는 git commit 과 push 사이의 단계, pre-commit 부분에서 Ollama와의 요청/응답을 포함한 파이썬 스크립트를 실행하여 자동화하게끔 작성했다.
1
2
3
4
5
6
7
ALGO_FILES=$(git diff --cached --name-only | grep "^src/ver2/.*\.java$")
if [ -z "$ALGO_FILES" ]; then
exit 0
fi
python3 scripts/auto_commit_msg.py /tmp/dummy_msg.txt
Ollama 도입 배경
LLM을 도입하기로 결정했을 때의 고민되는 부분이 있었다. 바로 비용 부분인데, 사실 이 부분에서는 기존에 사용하던 LLM(chat gpt, claude)의 API로 주고받으면 편리하긴하다. 이 부분은 유료이다. 물론 변경사항이 알고리즘 문제 .java 파일 하나여서 토큰의 소비가 그렇게 크진 않을 테지만 이 부분을 아에 무료화 할 수 있다면 이 방법을 선택하지 않을 이유가 없다.
이 이유로 Ollama를 활용하기로 결정했다. Ollama에서 무료로 풀려있는 모델들을 활용하기로 했는데 선택하는 기준은 다음과 같다. 
- 한글 지원이 잘 될 것
- 디스크에 저장하는 것인 만큼 모델의 크기가 적당한 것
찾아보다보니 이런(LLM 한국어 사용성 순위 ) 사이트가 있었고 이를 참고해서
qwen3:8b @latest 모델로 결정했다.
자동화 flow
모델을 결정하고 설계한 자동화 flow는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
git add .
↓
git commit
↓
pre-commit (LLM 활용)
- Python Script 실행
1. 변경 사항(java 파일)의 주석에 적힌 문제 링크로 문제 번호, 문제 이름 분석 및 추출 (추출 형식: Leet|1343|Number of Sub-arrays of Size K and Average Greater than or Equal to Threshold)
2. 문제 이름에 맞는 패키지 생성 및 java 파일 이동
3. 문제에 맞는 readme 생성
4. git commit -m "feat: Leet_1343_Number of Sub-arrays of Size K and Average Greater than or Equal to Threshold"
- git add .
↓
git commit
↓
git push
↓
기존 actions(메인 readme, blog post 업데이트) 트리거
파이썬 스크립트(auto_commit_msg.py)
Ollama는 Python에서 간편하게 사용할 수 있도록 공식 라이브러리를 제공한다.
1
pipx install ollama
위에 라이브러리를 import 받고 내가 로컬에 가지고 있는 모델에 작성한 프롬프트를 보내게끔 작성하면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
import ollama
def analyze_with_ollama(problem_link):
prompt = f""" prompt
"""
response = ollama.chat(
model='qwen3:8b',
messages=[{'role': 'user', 'content': prompt}],
options={'temperature': 0.2}
)
result = response['message']['content'].strip().split('\n')[0]
프롬프트
초기에 작성한 프롬프트는 아래와 같다.
한글 프롬프트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
"""전달해준 문제 링크를 분석해서 다음 정보를 추출해줘.
문제 링크: {problem_link}
추출할 정보:
1. 플랫폼 (백준/리트코드/프로그래머스)
2. 문제 번호 (플랫폼이 프로그래머스면 문제번호는 생략)
3. 문제 이름
응답 형식 (반드시 이 형식으로):
플랫폼|문제번호|문제이름
문제 이름 처리 규칙:
1. 한글 문제: 띄어쓰기만 제거, 나머지는 원본 그대로
- "DFS와 BFS" → "DFS와BFS"
- "이진 검색 트리" → "이진검색트리"
2. 영문 문제: 각 단어 첫글자 대문자, 띄어쓰기는 언더바(_)
- "k radius subarray averages" → "K_Radius_Subarray_Averages"
- "two sum" → "Two_Sum"
3. 특수문자는 제거하지 말고 그대로 유지
플랫폼별 예시:
- 백준: BOJ|1260|DFS와BFS
- 백준: BOJ|2580|스도쿠
- 리트코드: Leet|2090|K_Radius_Subarray_Averages
- 리트코드: Leet|1|Two_Sum
- 프로그래머스: PGMS||네트워크 (문제 번호 없으면 비워두기)
- 프로그래머스: PGMS||타겟넘버
규칙:
- 반드시 "플랫폼|문제번호|문제이름" 형식으로만 답해줘
- 다른 설명이나 부연 설명 절대 추가하지 마
- 띄어쓰기는 언더바(_)
- 한 줄로만 답해줘"""
하지만 응답 속도가 평균적으로 40초에서 1분까지 걸리는 것을 확인할 수 있었다.

커밋이 일회성에 가깝고 바로 다른 커밋이 들어갈 가능성이 적어서 시간이 길어져도 상관은 없었지만 블로그 글까지의 actions가 빠르게 돌아가면 좋으니 프롬프트를 영어로 작성하면 더 좋지 않을까 생각해서 영어로 작성해보았다.
영어 프롬프트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
"""Extract information from this problem URL:
{problem_link}
Required information:
1. Platform (BOJ for 백준, Leet for LeetCode, PGMS for Programmers)
2. Problem number (skip if Programmers)
3. Problem title
Response format (must follow exactly):
Platform|Number|Title
Title formatting rules:
1. Korean problems: Remove spaces only, keep everything else
- "DFS와 BFS" → "DFS와BFS"
- "이진 검색 트리" → "이진검색트리"
2. English problems: Capitalize first letter of each word, replace spaces with underscores
- "k radius subarray averages" → "K_Radius_Subarray_Averages"
- "two sum" → "Two_Sum"
- "container with most water" → "Container_With_Most_Water"
3. Replace hyphens (-) with underscores (_)
4. Keep all other special characters
Platform-specific examples:
- BOJ (백준): BOJ|1260|DFS와BFS
- BOJ (백준): BOJ|2580|스도쿠
- Leet (LeetCode): Leet|2090|K_Radius_Subarray_Averages
- Leet (LeetCode): Leet|1|Two_Sum
- Leet (LeetCode): Leet|11|Container_With_Most_Water
- PGMS (Programmers): PGMS||네트워크 (leave number empty)
- PGMS (Programmers): PGMS||타겟넘버
Critical rules:
- Output ONLY in "Platform|Number|Title" format
- NO explanations or additional text
- Replace ALL spaces with underscores in titles
- Output exactly ONE line
- If Programmers platform, use || (empty number field)"""
프롬프트를 수정하고 나니 응답속도가 10초에서 18초까지 개선이 되는 것을 확인할 수 있었다.

1
2
3
4
5
6
- 백준: BOJ|1260|DFS와BFS
- 백준: BOJ|2580|스도쿠
- 리트코드: Leet|2090|K_Radius_Subarray_Averages
- 리트코드: Leet|1|Two_Sum
- 프로그래머스: PGMS||네트워크 (문제 번호 없으면 비워두기)
- 프로그래머스: PGMS||타겟넘버
응답은 다음과 같은 형식으로 오도록 프롬프트에 작성하였고, 이를 파싱하기 위해 메서드를 하나 작성해주었다.
1
2
3
4
5
6
7
def generate_commit_message(platform, number, title):
if platform == "PGMS":
return f"feat: {platform}_{title}"
elif number:
return f"feat: {platform}_{number}_{title}"
else:
return f"feat: {platform}_{title}"
이 이후에 전에 작성했던 scrpit와 actions를 이이주면 작업이 끝난다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
apple@appleui-MacBookPro-2 Algorithm % git add .
apple@appleui-MacBookPro-2 Algorithm % git commit
-------------------------------------------------
ollama 시작
디렉토리명: Leet_460_LRU_Cache
커밋 메시지: feat: Leet_460_LRU_Cache
README 생성: src/ver2/Leet_460_LRU_Cache/README.md
디렉토리명: Leet_460_LRU_Cache
커밋 메시지: feat: Leet_460_LRU_Cache
README 생성: src/ver2/Leet_460_LRU_Cache/README.md
pushing...
Current branch main is up to date.
오브젝트 나열하는 중: 10, 완료.
오브젝트 개수 세는 중: 100% (10/10), 완료.
Delta compression using up to 11 threads
오브젝트 압축하는 중: 100% (7/7), 완료.
오브젝트 쓰는 중: 100% (7/7), 1.02 KiB | 1.02 MiB/s, 완료.
Total 7 (delta 4), reused 0 (delta 0), pack-reused 0 (from 0)
remote: Resolving deltas: 100% (4/4), completed with 3 local objects.
To https://github.com/choijw1004/Algorithm.git
7e21c87..7a5a1e6 main -> main
[main 7a5a1e6] feat: Leet_460_LRU_Cache
2 files changed, 79 insertions(+)
create mode 100644 src/ver2/Leet_460_LRU_Cache/README.md
create mode 100644 src/ver2/Leet_460_LRU_Cache/Solution.java
apple@appleui-MacBookPro-2 Algorithm %
성공이다.
마치며
생각보다 지금 모델의 성능이 괜찮아서 아직까지는 문제 없이 사용하고 있다. 로컬에서 가볍게 작업할 때에는 Ollama의 이 모델을 사용해봐도 괜찮을 것 같다. 이젠 진짜 자동화가 끝이길 바라며 글을 마친다.