웹 크롤러 설계
웹 크롤러의 설계 방식에 대해
웹 크롤러 설계
웹 크롤러 개요
웹 크롤러는 웹 페이지를 자동으로 수집하는 시스템입니다. 작은 규모의 경우 몇 시간 만에 끝낼 수도 있지만, 대규모 검색 엔진용 크롤러는 수년간 유지·관리해야 하는 복잡한 시스템이 될 수 있습니다.
웹 크롤러의 기본 알고리즘은 다음과 같습니다.
- URL 집합을 입력
- 해당 URL의 웹 페이지를 다운로드
- 다운로드한 페이지에서 새로운 URL을 추출
- 추출된 URL을 다시 큐에 넣고 위 과정을 반복
설계 요구사항
- 규모 확장성: 병렬 처리와 분산 크롤링이 필요합니다.
- 안정성: 잘못된 HTML, 무응답 서버, 악성 링크 등 비정상적인 상황에 대응할 수 있어야 합니다.
- 예절(Politeness): 동일 사이트에 과도한 요청을 보내지 않아야 합니다.
- 확장성: 이미지, 동적 렌더링 등 새로운 콘텐츠 타입을 쉽게 지원할 수 있어야 합니다.
개략적 규모 추정
- 월 10억 페이지 다운로드
- 평균 페이지 크기: 500KB
- QPS: 약 400 (최대 800)
- 월 저장 용량: 500TB
- 5년치 누적 데이터: 30PB
시스템 컴포넌트
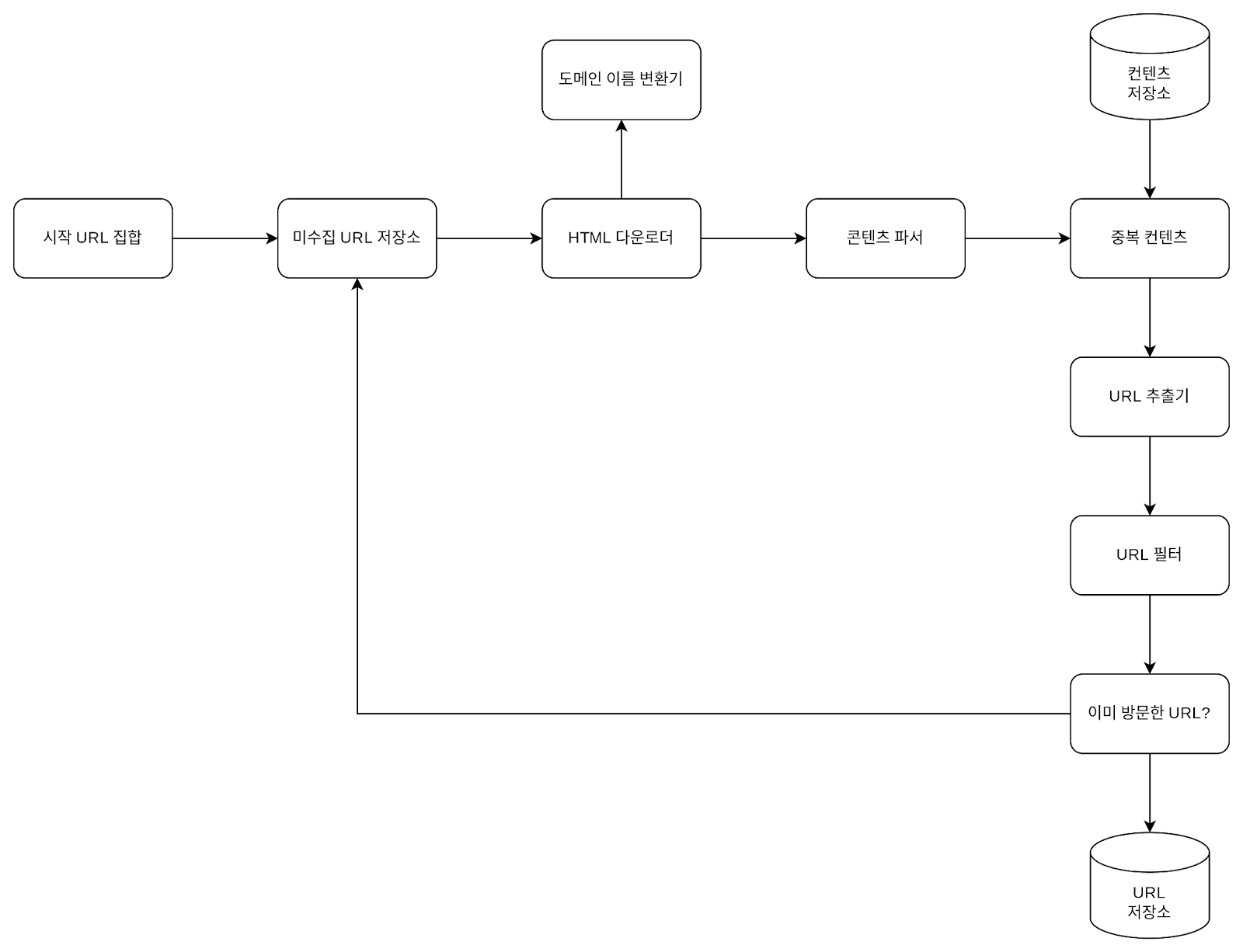 아래는 위의 아키텍쳐에서 사용되는 컴포넌트들의 정의와 역할입니다.
아래는 위의 아키텍쳐에서 사용되는 컴포넌트들의 정의와 역할입니다.
- 시작 URL 집합: 크롤링 출발점입니다.
- 미수집 URL 저장소: 다운로드할 URL을 보관하는 큐입니다.
- HTML 다운로더: 실제 웹 페이지를 다운로드합니다.
- 도메인 이름 변환기: URL을 IP로 변환하며, 캐싱을 통해 성능을 높입니다.
- 콘텐츠 파서: HTML을 파싱하고 형식을 검증합니다.
- 중복 콘텐츠 판별기: 해시나 Fingerprint로 중복 여부를 판별합니다.
- 콘텐츠 저장소: 디스크 기반 저장소, 자주 쓰이는 데이터는 메모리에 캐시합니다.
- URL 추출기: HTML에서 링크를 절대 경로로 변환하여 추출합니다.
- URL 필터: 확장자, 블랙리스트, 오류 URL을 걸러냅니다.
- URL 저장소: 방문 완료된 URL을 관리합니다 (블룸 필터, 해시테이블 활용).
웹 크롤러 작업 흐름
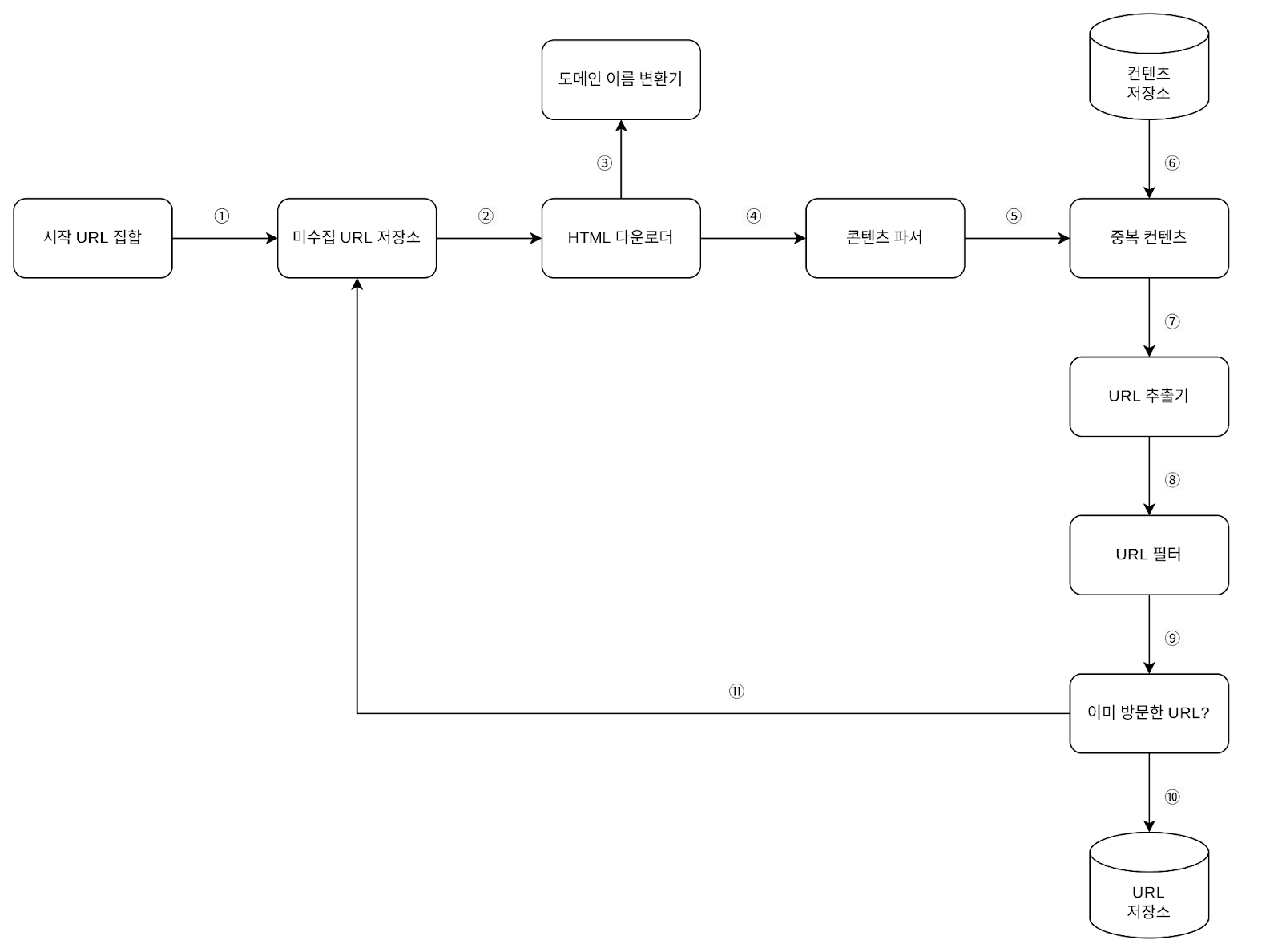
- 시작 URL을 미수집 URL 저장소에 저장합니다.
- HTML 다운로더가 큐에서 URL을 가져옵니다.
- 도메인 변환 후 페이지를 다운로드합니다.
- 파싱 및 검증 절차를 거칩니다.
- 중복 콘텐츠 여부를 확인합니다.
- 새로운 콘텐츠는 저장 후 URL 추출기로 전달합니다.
- URL 추출 → 필터링 → 중복 검사 과정을 거칩니다.
- 새로운 URL은 저장소에 기록하고, 다시 미수집 큐에 넣습니다.
탐색 방식
웹은 유향 그래프(directed graph)와 같습니다. 페이지는 노드고 하이퍼 링크는 엣지(edge)라고 보면 되기 때문에 크롤링 프로세스는 이 유향 그래프를 엣지를 따라 탐색하는 과정입니다.
- DFS: 깊이 제한이 불명확하여 크롤링에는 부적합합니다.
- BFS: 일반적으로 사용되며, FIFO 큐 기반으로 동작합니다.
미수집 URL 저장소
예의: 동일 호스트는 하나의 큐에만 배치하고 요청 간 간격을 둡니다.
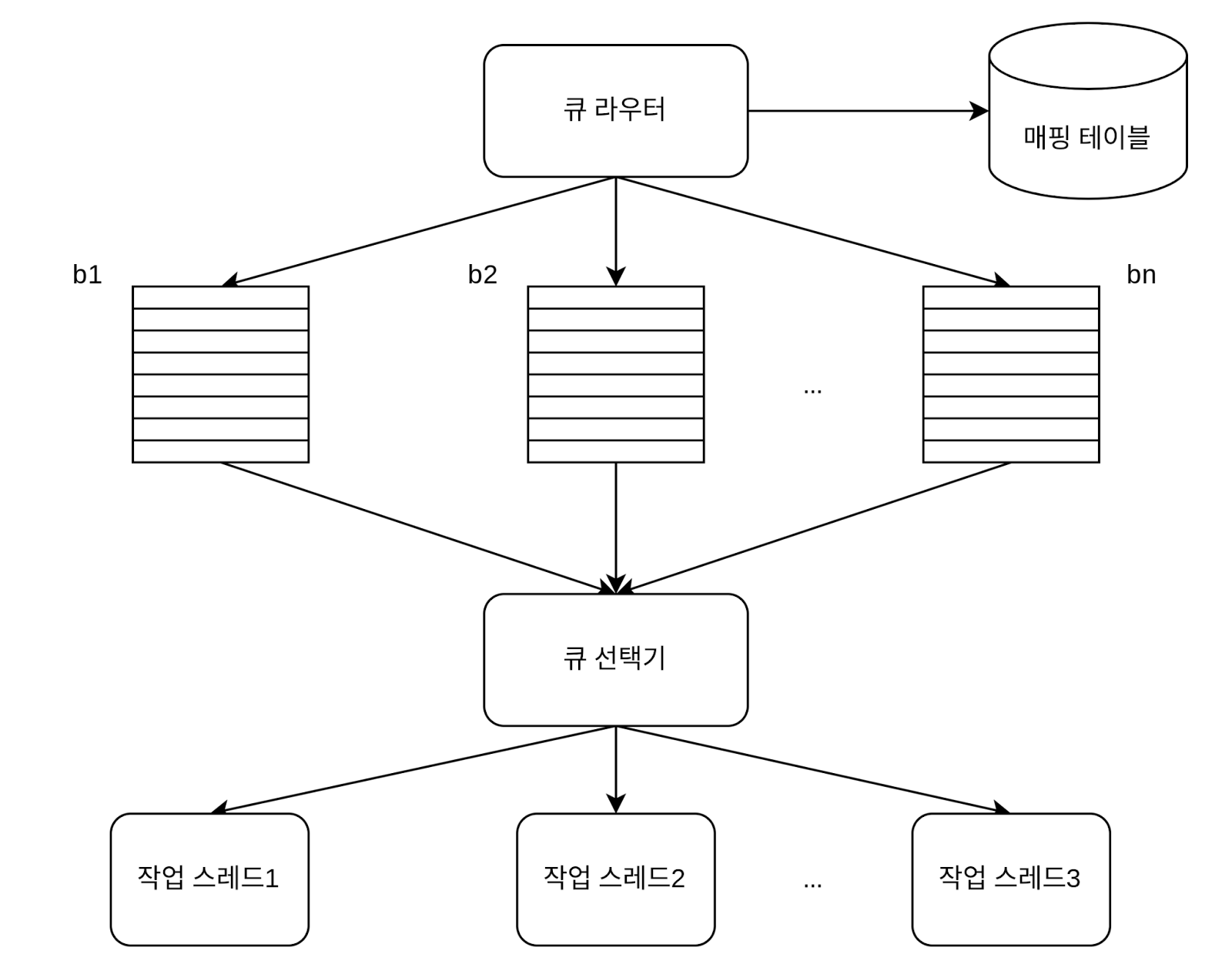
- 우선순위: PageRank, 트래픽, 갱신 빈도 등을 기준으로 중요한 페이지를 먼저 수집합니다.
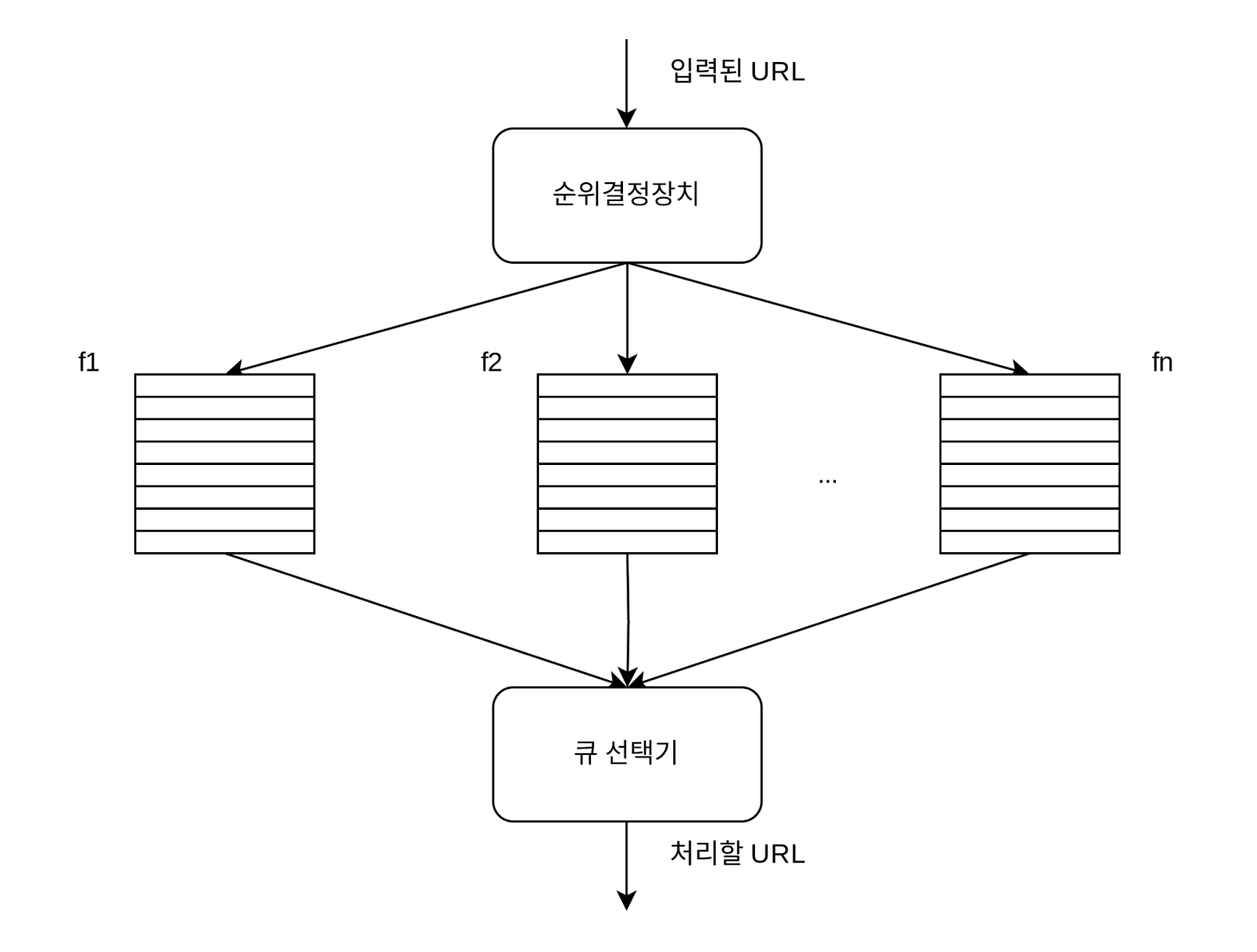
- 전면 큐 / 후면 큐 구조: 우선순위 관리와 예절을 동시에 만족시킵니다.
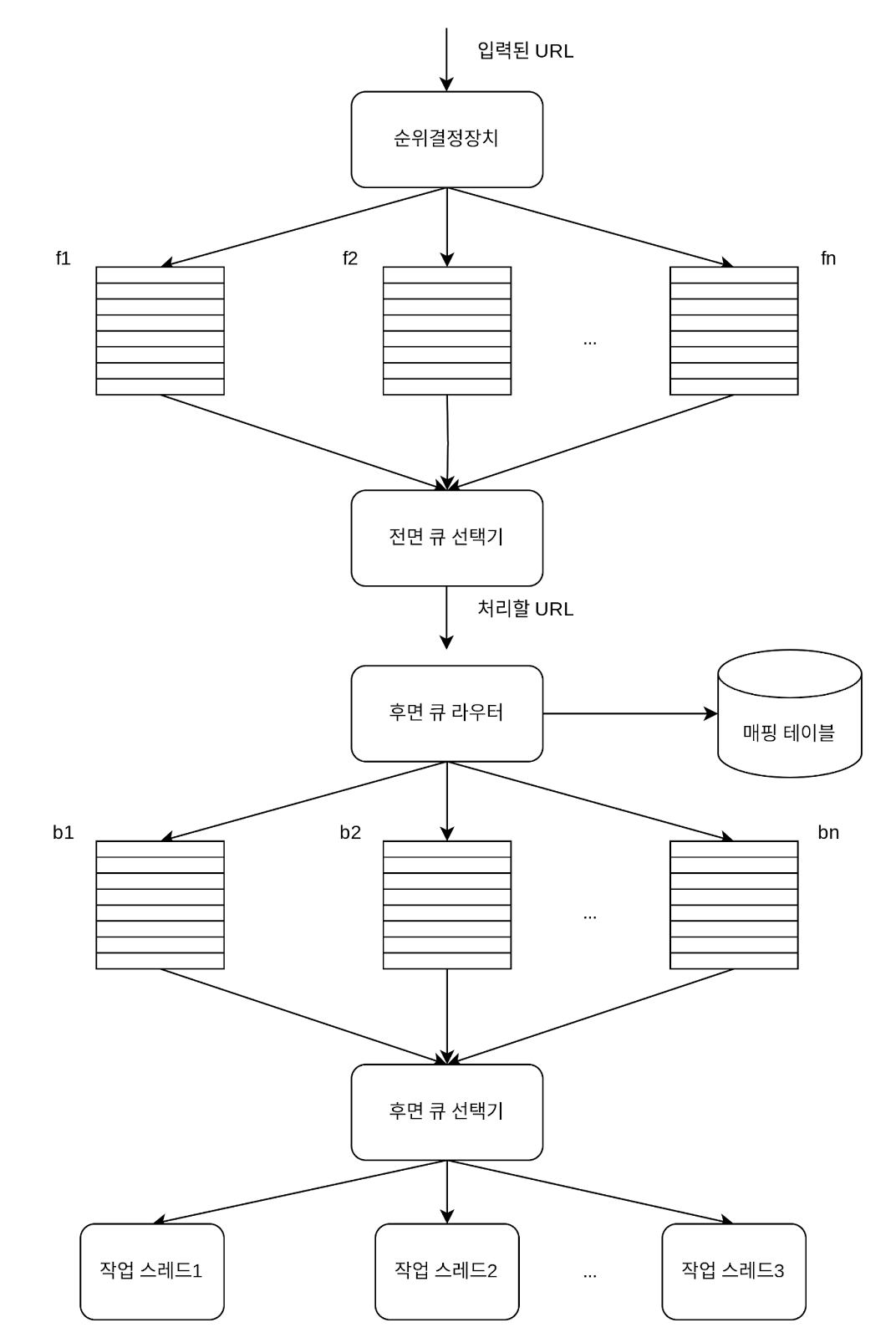
신선도 유지
- 웹 페이지는 수시로 변경되므로 재수집이 필요합니다.
- 중요 페이지는 더 자주 재수집하며, 변경 이력 기반 접근이 가능합니다.
성능 최적화
- 분산 크롤링: 여러 서버와 스레드를 활용합니다.
- DNS 캐시: 도메인→IP 매핑을 캐싱하여 응답 속도를 개선합니다.
- 지역성(Locality): 지역별로 서버를 배치하면 다운로드 속도가 향상됩니다.
- 짧은 타임아웃: 무응답 서버로 인한 대기 시간을 줄입니다.
안정성 및 확장성
- 안정 해시: 서버 증설/삭제 시 부하를 균형 있게 분산합니다.
- 상태 저장: 장애 복구를 위해 크롤링 상태와 수집 데이터를 지속적으로 저장합니다.
- 예외 처리: 일부 실패가 전체 중단으로 이어지지 않도록 설계합니다.
- 데이터 검증: 오류 데이터를 걸러 시스템 장애를 예방합니다.
- 확장성: 새로운 콘텐츠 타입을 쉽게 추가할 수 있도록 설계합니다.
문제 있는 콘텐츠 처리
- 중복 콘텐츠: 해시·check sum으로 중복을 판별합니다.
- 거미 덫(Spider Trap): 무한 루프를 유발하는 URL은 길이 제한이나 필터링으로 방지합니다.
- 데이터 노이즈: 광고, 스크립트, 스팸 URL을 제거합니다.
This post is licensed under CC BY 4.0 by the author.