쓰레드란 무엇인가?
OS의 thread 와 JVM의 thread에 대해
쓰레드란 무엇인가?
쓰레드(Thread)는 프로세스 내에서 CPU 스케줄링 단위로 동작하며, 경량 프로세스(Lightweight Process)라고도 합니다.
프로세스 vs 쓰레드
- 프로세스: 운영체제가 할당하는 메모리 공간과 자원의 단위
- 쓰레드: 같은 프로세스 내에서 코드·데이터·힙을 공유하며, 스택만 독립 관리
쓰레드를 사용하는 이유
- CPU 활용률 향상 (멀티코어 활용)
- I/O 대기 시간 중 다른 작업 수행
- 시스템 반응성(Reactivity) 개선
쓰레드의 장단점
| 구분 | 장점 | 단점 |
|---|---|---|
| 성능 | - 멀티코어 병렬 처리로 처리량 증가 - I/O 대기 시 다른 작업 전환 가능 | - 문맥 전환(Context Switch) 오버헤드 - 쓰레드 생성/소멸 비용 |
| 설계 | - 논리적 작업 분리로 코드 가독성↑ | - 동시성 버그(경쟁 상태, 데드락) 발생 위험↑ |
| 운영 | - 반응형 서버 구현 가능 | - 디버깅·트래픽·리소스 튜닝 복잡성 증가 |
User 쓰레드와 OS 쓰레드
| 구분 | OS 쓰레드 (Kernel Thread) | User 쓰레드 (User Thread) |
|---|---|---|
| 관리 주체 | 운영체제 커널 | JVM(런타임 라이브러리) |
| 생성 방식 | clone() / pthread_create() 시스템콜 호출 | new Thread() 후 JVM이 시스템콜로 위임 |
| 스케줄링 | 커널 스케줄러가 직접 제어 | JVM이 OS 쓰레드로 매핑 후 자체 스케줄링 가능 |
| 블로킹 영향 | 해당 쓰레드만 블로킹 | One-to-One 매핑으로 개별 쓰레드 블로킹 |
| 멀티코어 활용 | 완전 활용 가능 | 매핑된 OS 쓰레드 수만큼 활용 |
| 문맥 전환 비용 | 높음 (커널 모드 전환 오버헤드) | 낮음 (사용자 공간 스케줄링 시 라이브러리 구현) |
컨텍스트 스위칭(Context Switch)
정의 & 필요성 컨텍스트 스위칭이란 현재 실행 중인 쓰레드(또는 프로세스)의 CPU 레지스터 상태를 저장하고, 다른 쓰레드의 상태를 복원해 실행을 이어 가는 과정입니다. 멀티태스킹 환경에서 여러 쓰레드를 공정하게 돌리기 위해 반드시 거쳐야 하는 단계입니다.
- 문맥 전환의 단계
- Trap/Interrupt: 타이머 인터럽트나 I/O 인터럽트 발생
- 커널 진입: CPU가 커널 모드로 전환, 현재 레지스터(RIP, RSP, 일반 레지스터 등) 저장
- 스케줄러 호출: 커널 스케줄러가 렌너블(runnable) 큐에서 다음 실행 대상 선택
- 레지스터 복원: 선택된 쓰레드의 PCB(Process Control Block)에 저장된 레지스터 값 복원
- 유저 모드 복귀: 복원된 상태로 사용자 공간 쓰레드 실행 재개
오버헤드 요소
- 레지스터 저장·복원 비용: 수십 개의 레지스터를 메모리에 쓰고 읽는 시간
- TLB(Translation Lookaside Buffer) 플러시: 프로세스 간 주소 공간 전환 시 페이지 매핑 캐시 초기화
- 캐시 미스 증가: 새 쓰레드의 작업 영역이 캐시에 없으면 메모리 접근 지연
- 커널·유저 모드 전환 비용: 특권 레벨 변경(trap gate) 오버헤드
영향 & 튜닝 포인트
- 과도한 동시 쓰레드: 쓰레드 수가 코어 수보다 훨씬 많아지면 문맥 전환 빈도 급증
- 스레드 풀 크기 최적화: JVM/톰캣 레이어에서 적절한 풀 크기로 제한
- CPU Affinity(선호도) 설정: 핵심 코어에 특정 쓰레드를 고정해 캐시 지역성(Locality) 향상
- 가상 쓰레드 / 논블로킹 I/O 활용: 물리 쓰레드 수를 줄여 문맥 전환 부담 경감
Java(JVM) 쓰레드 모델
자바(JVM)는 One-to-One 모델을 채택하여, User 쓰레드와 OS 쓰레드를 1:1로 매핑합니다.
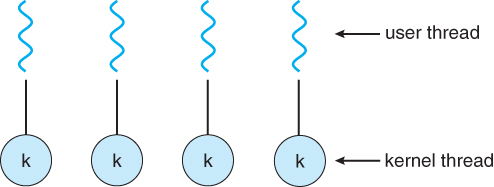
- One-to-One:
java.lang.Thread인스턴스 하나당 개별 OS 쓰레드가 생성됩니다. - Java는 Many-to-One 또는 Many-to-Many 모델을 지원하지 않습니다.
Tomcat과 쓰레드
Connector & Thread Pool
- Tomcat Connector (BIO / NIO / APR)가 클라이언트 요청을 받아 Executor(쓰레드풀)에 전달합니다.
기본 Thread-per-Request 모델:
- 요청이 들어오면 쓰레드풀에서 쓰레드 할당
- 서블릿
service()실행 - 응답 완료 시 쓰레드 반환
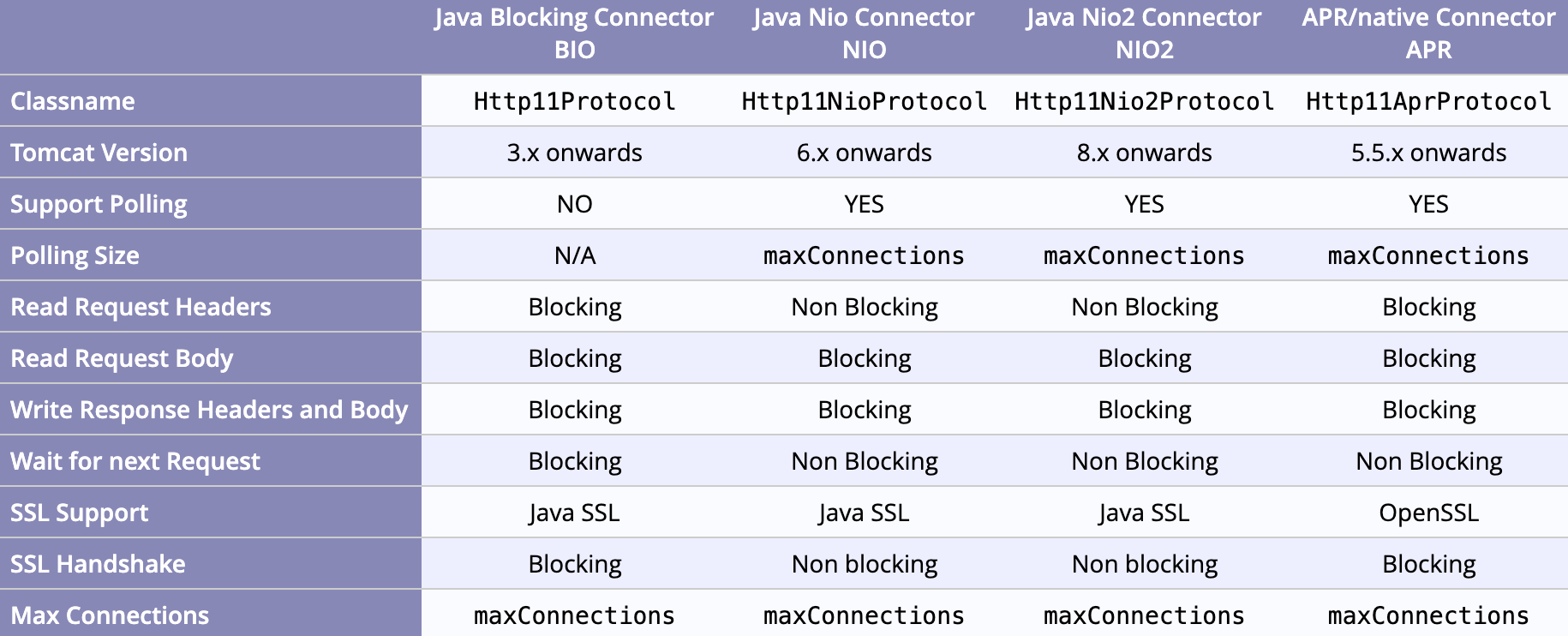
BIO (Blocking I/O) Connector
- 각 요청마다 Blocking Socket 사용 -> 쓰레드 점유
- 동시 요청 증가 시 쓰레드 수 확장 필요 -> 컨텍스트 스위칭 & 메모리 오버헤드 증가
NIO (Non-Blocking I/O) Connector
- Selector 기반으로 소수 쓰레드가 다수 커넥션 감시
- I/O 이벤트 발생 시에만 작업 쓰레드로 디스패치
- Servlet 3.0 Async 지원 시, I/O 대기 중 쓰레드 반환 가능
Thread Pool 튜닝 포인트
maxThreads: 최대 동시 처리 쓰레드 수 (default 200)acceptCount: 큐에 대기 가능한 최대 연결 수 (default 100)minSpareThreads/maxSpareThreads: 유휴 쓰레드 수 (default 10)connectionTimeout: 클라이언트 연결 대기 시간 (default 20000 ms)
BIO, NIO, APR이란?
Tomcat이 외부(브라우저·HTTP 클라이언트)로부터 TCP 연결을 받아들이는 진입점입니다. 예를 들어 http://localhost:8080/hello 같은 URL로 요청이 들어오면, 그 요청을 받아들여 HTTP 메시지(요청 헤더·바디)를 파싱하고 내부적으로 Request 객체로 만듭니다.
1. BIO (Blocking I/O) 커넥터 흐름
TCP 연결 수락 (Accept)
- Main Acceptor 쓰레드가
ServerSocket.accept()를 호출하여 클라이언트 연결을 블로킹 대기 - 새 연결이 오면 소켓 객체(
Socket)를 반환
- Main Acceptor 쓰레드가
Worker 쓰레드 할당
- 연결된 소켓을 쓰레드 풀에서 꺼낸 Worker 쓰레드에게 넘김
요청 읽기(Blocking Read)
- Worker 쓰레드가
InputStream.read()를 호출 - 클라이언트가 보낸 HTTP 요청 전체(헤더+바디)가 도착할 때까지 블로킹
- Worker 쓰레드가
서블릿 실행
- 요청을 파싱해
HttpServletRequest/Response객체를 만들고 service()→ Spring MVC 핸들러 실행
- 요청을 파싱해
응답 쓰기(Blocking Write)
OutputStream.write()로 응답 바이트를 전송, 완료될 때까지 블로킹
연결 종료 또는 유지
Connection: keep-alive이면 소켓을 재사용할 수 있지만,- 다음 요청도
read()호출 시 계속 블로킹
Worker 쓰레드 반환
- 하나의 요청 처리 완료 후 쓰레드를 풀로 반환
2. NIO (Non-Blocking I/O) 커넥터 흐름
TCP 연결 수락 (Accept)
- Acceptor 쓰레드가
ServerSocketChannel.accept()호출 (논블로킹) - 연결되자마자
SocketChannel반환
- Acceptor 쓰레드가
채널 등록 (Register)
- 새
SocketChannel을 Selector에OP_READ관심 설정으로 등록 - 여러 채널을 하나의 Selector가 관리
- 새
이벤트 감시 (Select Loop)
- Poller 쓰레드가
selector.select()호출 - 읽기/쓰기 이벤트가 발생한 채널만 리턴
- Poller 쓰레드가
읽기 준비 확인
selectedKeys()에서 읽기 가능(OP_READ) 채널을 꺼냄
Worker 쓰레드 할당
- 해당 채널의 읽기 작업만 Worker 쓰레드에 위임
- Worker는 블로킹이 아닌
read()→ 즉시 읽을 수 있는 만큼만 가져옴
서블릿 실행
- 파싱한 요청을 서블릿/컨트롤러에 전달, 동기 방식으로 처리
응답 쓰기
- 응답 데이터를 버퍼에 담아
SocketChannel.write()호출 - 만약 한번에 모두 쓰기 불가능하면,
OP_WRITE로 다시 Selector 등록 후 나중에 완료
- 응답 데이터를 버퍼에 담아
다음 이벤트 대기
- 처리 후 채널을 계속 Selector에 남겨둬 다음 읽기/쓰기 이벤트 감시
3. APR (Apache Portable Runtime) 커넥터 흐름
APR 커넥터는 “Native” I/O 라이브러리를 활용한 NIO와 유사한 논블로킹 모델이지만, 플랫폼 네이티브 API를 직접 사용합니다.
네이티브 Listener 쓰레드
- APR의
apr_socket_accept()호출 → 커널 쪽 네이티브 소켓 레벨에서 바로 수락 - Java 레이어가 아닌 C/C++ 라이브러리(토막
tcnative)에서 처리
- APR의
채널/소켓 풀 관리
- 연결 소켓을 APR 메모리 풀에 보관 → 객체 재사용, GC 오버헤드 최소화
이벤트 감시 (Native Poll/Proactor)
- Linux의
epoll/ BSD의kqueue등 네이티브 이벤트 알림 메커니즘 사용 - 이벤트가 오면 APR 스레드가 바로 콜백
- Linux의
Worker 쓰레드 위임
- 이벤트 처리 콜백 안에서 Java Worker 쓰레드에 요청 객체 전달
service()호출, 응답 생성
네이티브 쓰기
- APR의
apr_socket_send()등 네이티브 API로 응답 전송 - Java → 네이티브 호출 오버헤드는 있지만, 이후 I/O 경로는 모두 C 레벨에서 최적화
- APR의
풀로 반환
- 요청/응답 처리 완료 후 Java 쓰레드는 쓰레드풀로, 네이티브 소켓은 소켓 풀로 반환
요약 비교
| 단계 | BIO | NIO | APR (Native) |
|---|---|---|---|
| Accept | accept() 블로킹 | accept() 논블로킹 + Selector 등록 | apr_socket_accept() (네이티브) |
| Read | read() 블로킹 | read() 논블로킹 (OP_READ 감시) | apr_socket_recv() (네이티브) |
| Dispatch | Worker 쓰레드 직접 실행 | 이벤트 시 Worker 쓰레드 위임 | 네이티브 콜백 → Worker 쓰레드 위임 |
| Write | write() 블로킹 | write() 논블로킹 (OP_WRITE) | apr_socket_send() (네이티브) |
| 리소스 관리 | 소켓·쓰레드 단순 생성/소멸 | Selector + 채널 재사용 | APR 메모리풀 + 소켓풀 재사용 |
BIO는 단순하지만 동시성 한계가 명확하고, NIO는 자바 레이어에서 논블로킹을 지원하며 멀티플렉싱이 가능하며, APR은 네이티브 I/O를 활용해 한층 더 낮은 레이턴시와 효율을 제공합니다.